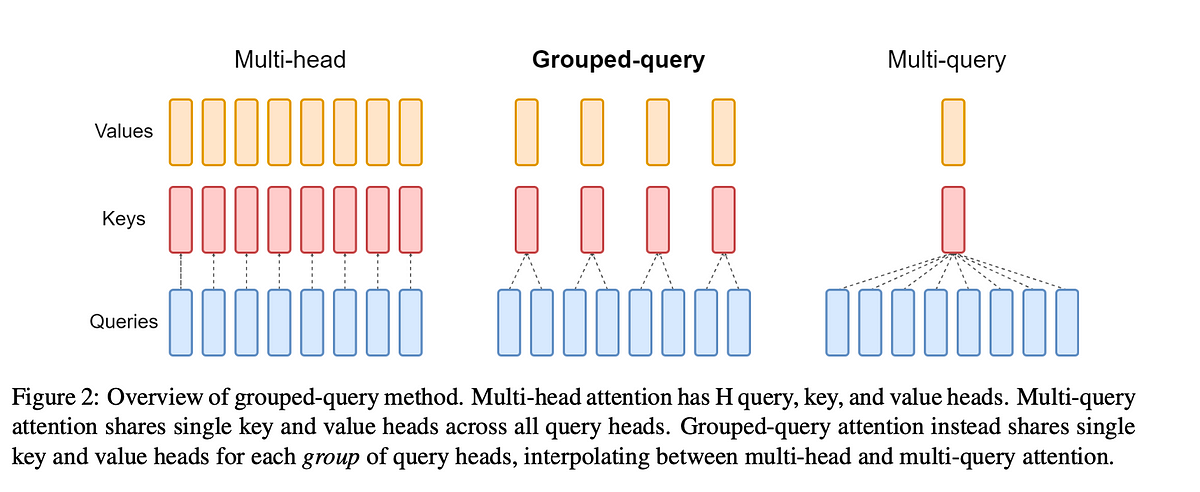
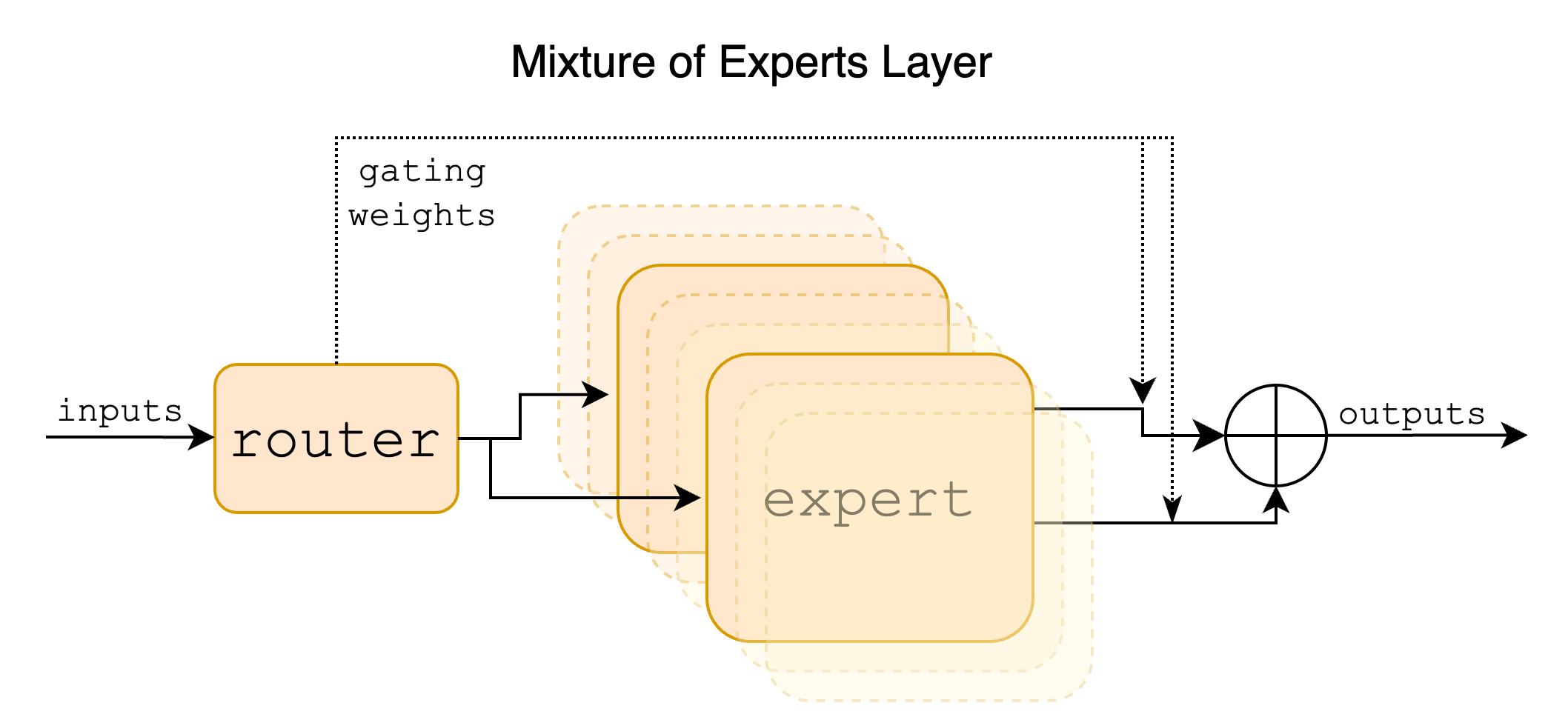
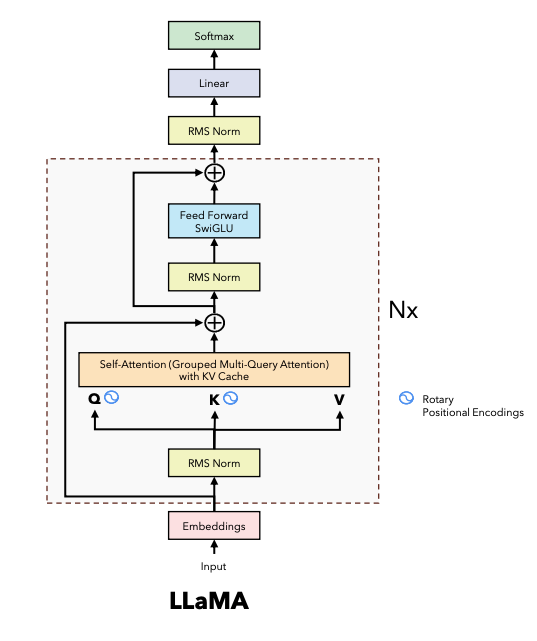
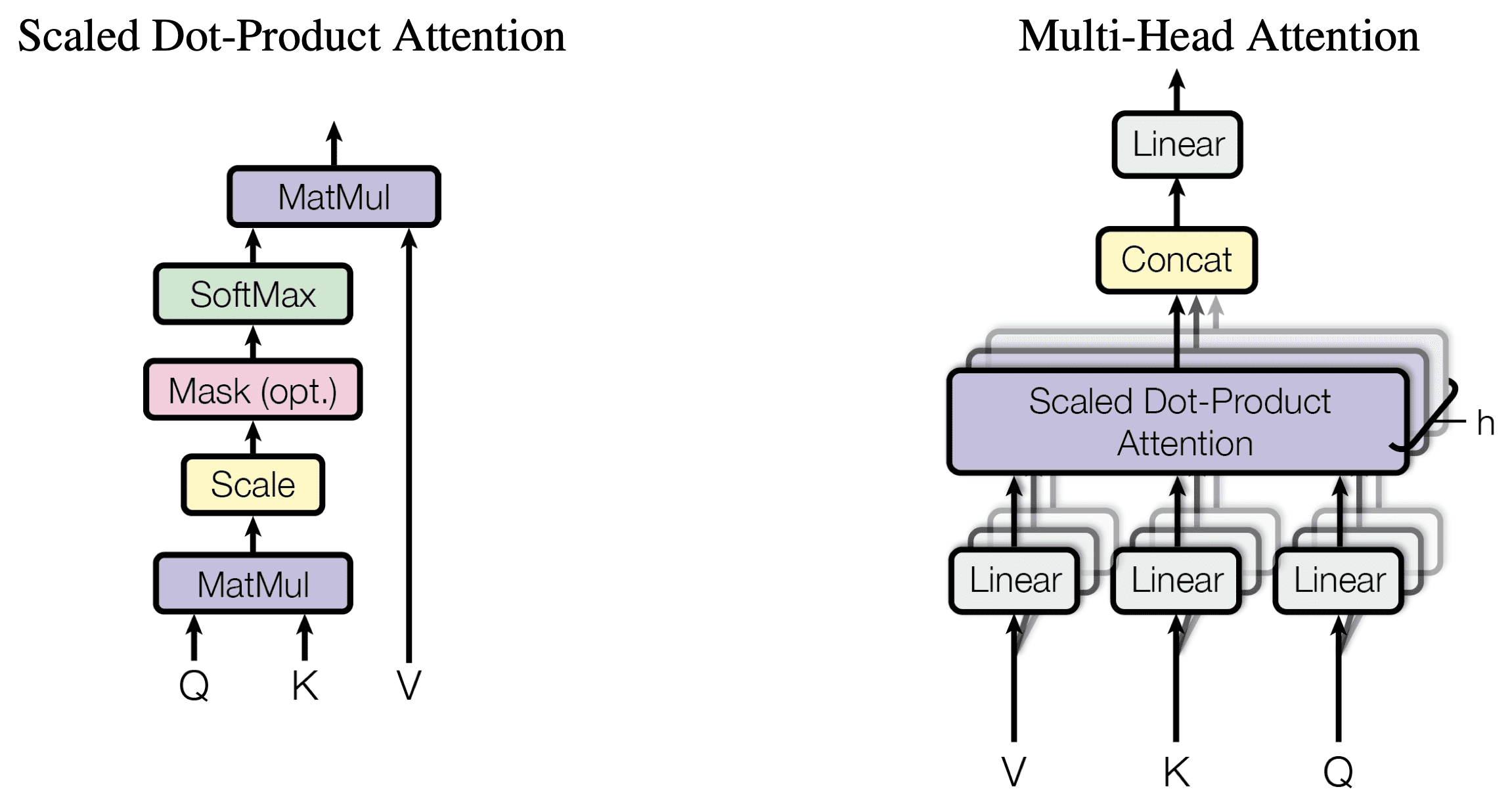
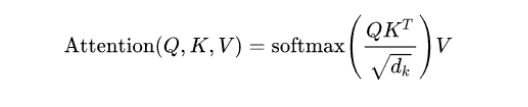During current advancement of LLM, many different attention methods beyond Multi-Head Attention (MQA) from original Transformer model have been proposed, such as Multi-Query Attention (MQA) from Falcon, Grouped-Query Attention (GQA) from Llama and Sliding-Window Attention (SWA) from Mistral. Both MQA and GQA aim to save GPU memory (i.e. reduce the size of Key & Value projection matrices during attention) and speed up attention calculation (i.e. reduce size of KV cache so that read data faster and support for large batch size) without too much model performance degradation. Sliding-Window attention (SWA) is a technique used in transformer models to limit the attention span of each token to a fixed size window around it, which reduces the computational complexity and makes the model more efficient.
This blog will implement all these different attention mechanisms from scratch using PyTorch.