KV Cache is an important technique used in transformer-decoder based models during inference, which can save much computation cost and make the inference faster.
Since the transformer-decoder based model is auto-regressive model, i.e. it generates new token one by one at each time step. Every time we get a new token, we append this new token to the input tokens of the model to generate a sequence of output tokens, the last token of output will be another new token. We repeat this generation process until we get the end of text token or hit to the limit of max sequence length.
During every inference step, we found we are only interested in the last token of model output tokens, which is a generated new token. But the old tokens have been generated again and again during each inference step due to the sequence to sequence mechanism of transformer-decoder based models. The model needs access to all the previous tokens to decide on which token to output during the masked self-attention stage, since they constitute its previous context.
Therefore, KV cache has been introduced to help model avoid doing repetitive computation in the attention calculation of inference and save GPU memory during inference.
The illustrated motivation of KV cache (source):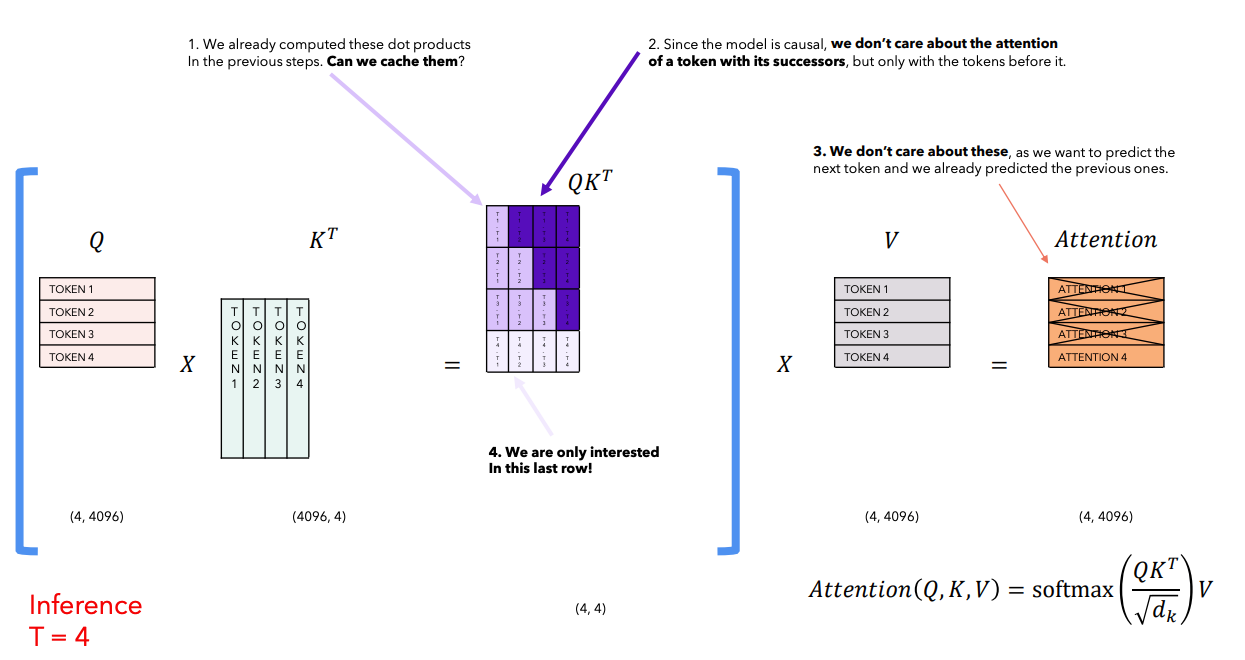
Here is the image of after we applying KV cache to generate new token (source):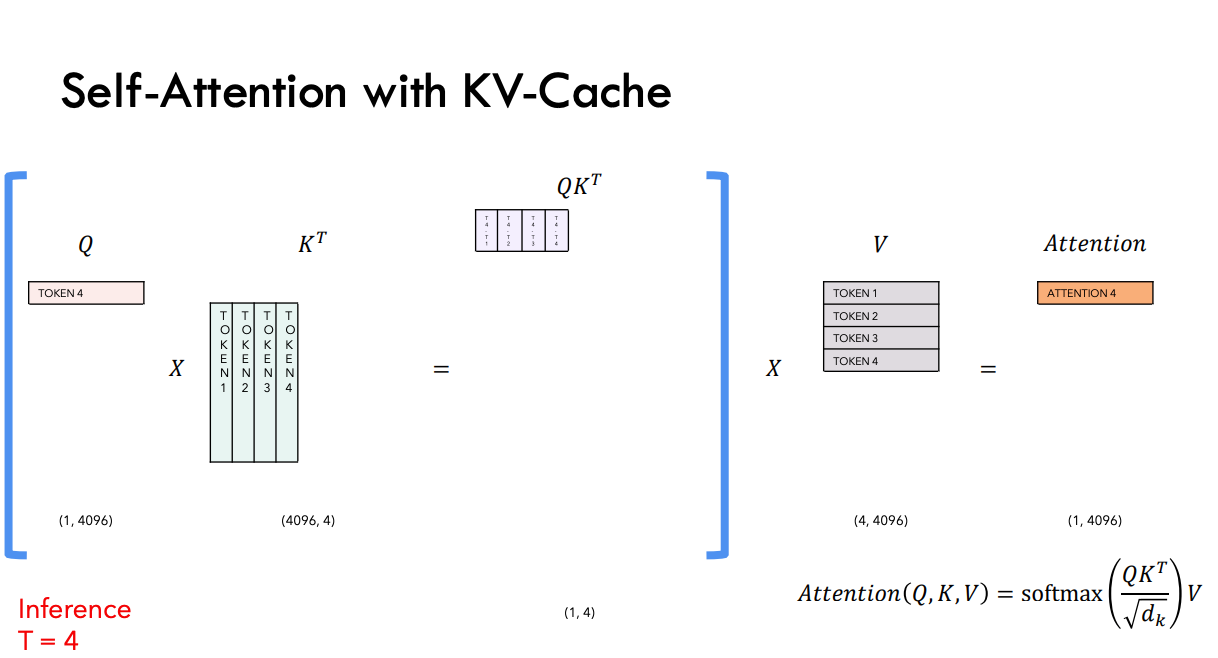
The Python implementation of KV Cache:
1 |
|
References:
- https://www.youtube.com/watch?v=Mn_9W1nCFLo
- https://github.com/hkproj/pytorch-llama-notes/blob/main/LLaMA_Final.pdf
- https://www.dipkumar.dev/becoming-the-unbeatable/posts/gpt-kvcache/
- https://github.com/jaymody/picoGPT/pull/7/files
- https://kipp.ly/transformer-inference-arithmetic/#kv-cache
- https://medium.com/@joaolages/kv-caching-explained-276520203249
- https://lilianweng.github.io/posts/2023-01-10-inference-optimization/