This blog will implement decoder-based model llama2 from scratch with PyTorch to get better understanding of model structure and some tricks used in the model.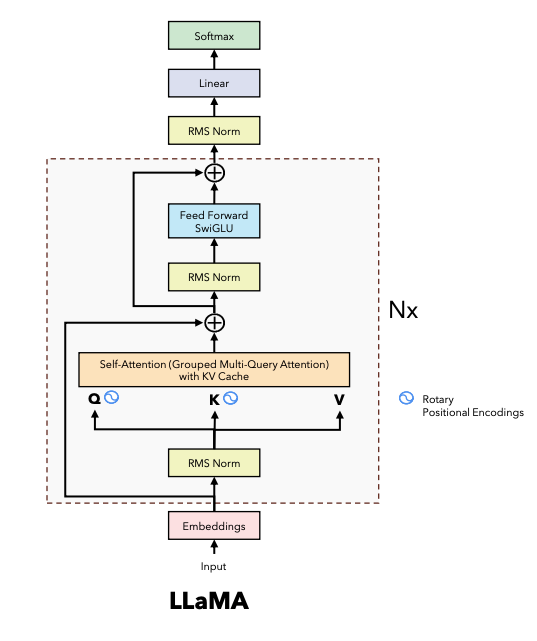
- RMSNorm implementation
- Rotary Position Embedding
- Grouped Query Attention
- SwiGLU activation function and FeedForward
- Llama2 model
- References
RMSNorm implementation
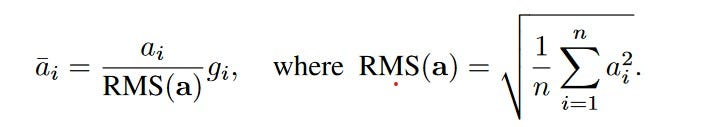
1 | from typing import Optional |
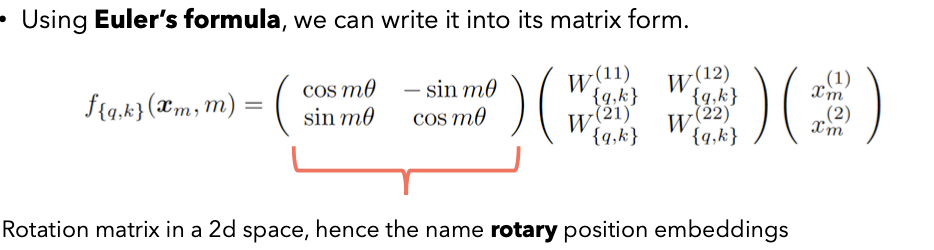
Rotary Position Embedding
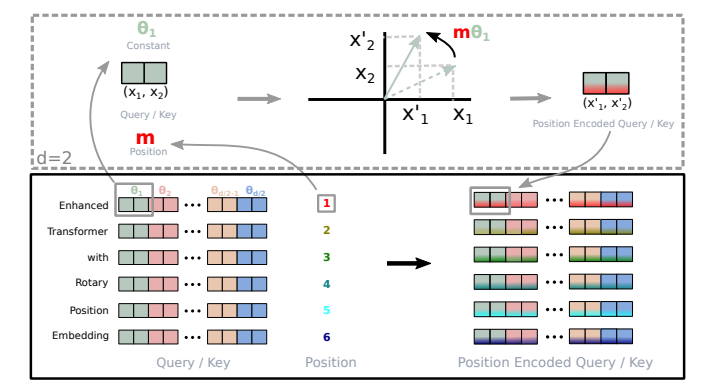
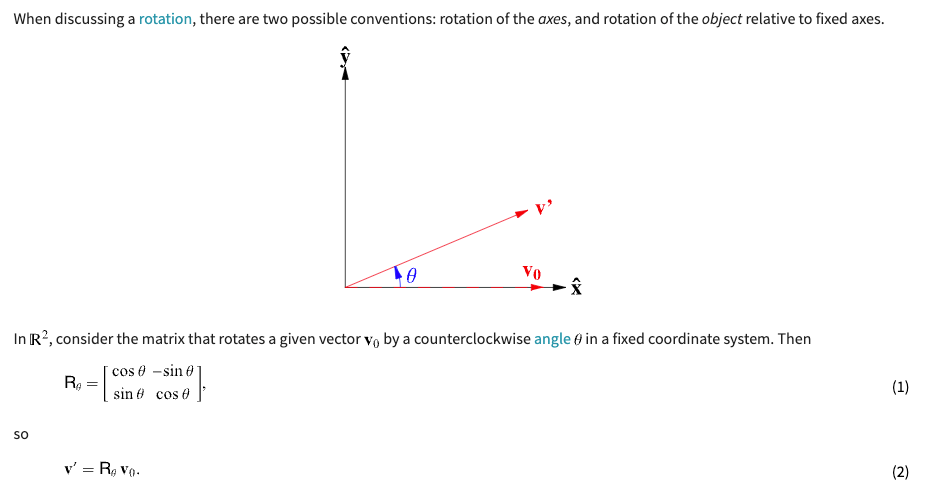
Background Knowledge:
- Can we find an inner product over the two vectors q (query) and k (key) used in the attention mechanism that only depends on the two vectors and the relative distance of the token they represent?
- The “intensity” of relationship between two tokens encoded with Rotary Positional Embeddings will be numerically smaller as the distance between them grows.
- The rotary position embeddings are only applied to the query and the keys, but not the values.
- The rotary position embeddings are applied after the vector q and k have been multiplied by the W matrix in the attention mechanism, while in the vanilla transformer they’re applied before.
1 | import torch |
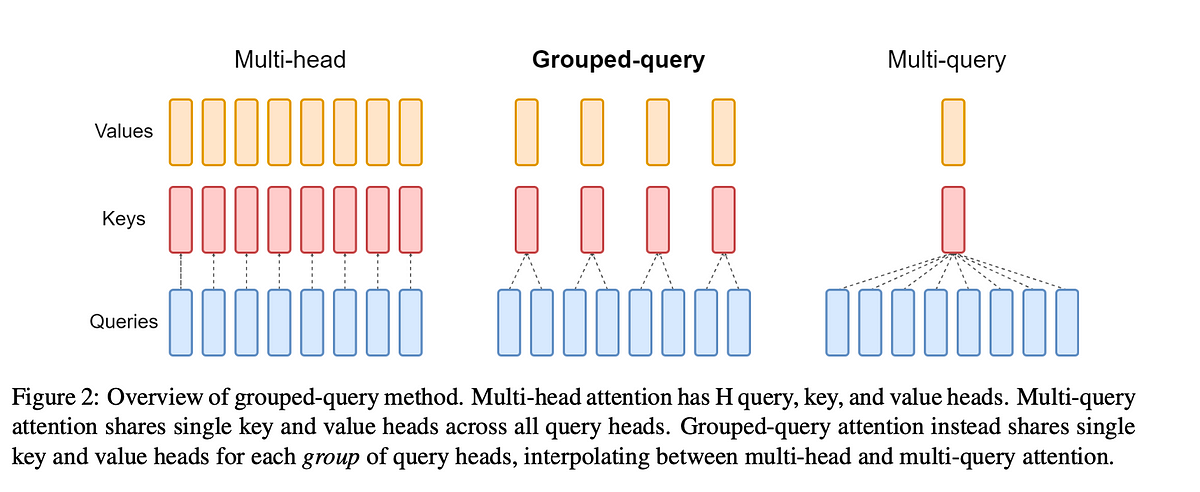
Grouped Query Attention
Motivation: Our goal should not only be to optimize the number of operations we do, but also minimize the memory access/transfers that we perform. Since the data transfer and memory access are always the bottlenecks in modern GPU, not computation operations.
This is a comprise between quality (multi-head attention) and speed (multi-query attention).
1 |
|
SwiGLU activation function and FeedForward
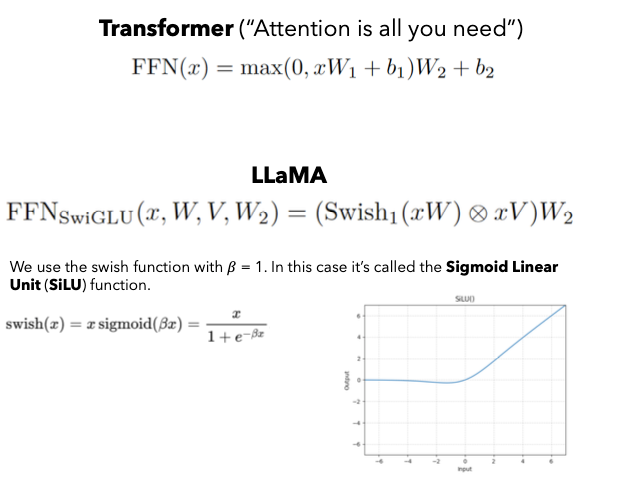

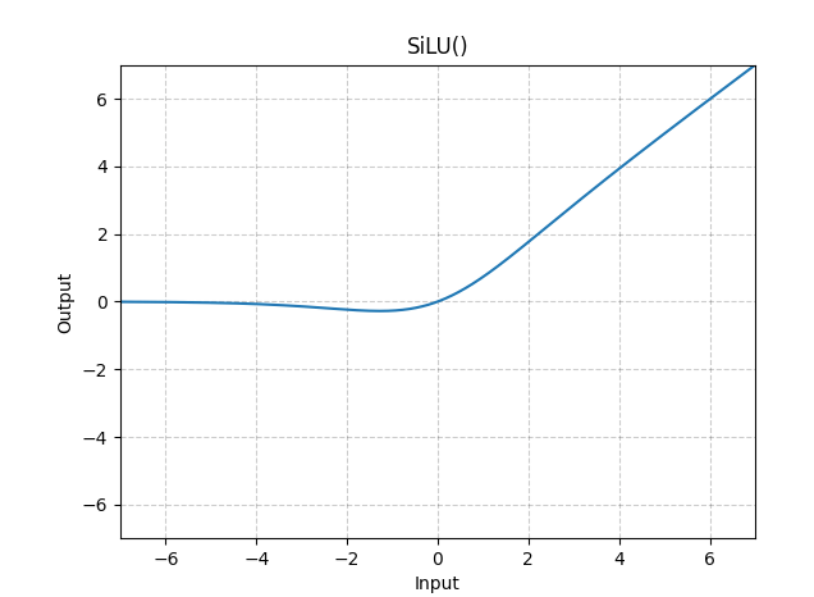
1 | class FeedFroward(nn.Module): |
Llama2 model
Put all above components together to get llama2 model.
Build blocks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class EncoderBlock(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = SelfAttention(args)
self.feed_forward = FeedForward(args)
# Normalization BEFORE the attention block
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
# Normalization BEFORE the feed forward block
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_complex: torch.Tensor):
h = x + self.attention.forward(
self.attention_norm(x), start_pos, freqs_complex
)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return outBuild whole model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Transformer(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
assert args.vocab_size != -1, "Vocab size must be set"
self.args = args
self.vocab_size = args.vocab_size
self.n_layers = args.n_layers
self.tok_embeddings = nn.Embedding(self.vocab_size, args.dim)
self.layers = nn.ModuleList()
for layer_id in range(args.n_layers):
self.layers.append(EncoderBlock(args))
self.norm = RMSNorm(args.dim, eps=args.norm_eps)
self.output = nn.Linear(args.dim, self.vocab_size, bias=False)
self.freqs_complex = precompute_theta_pos_frequencies(self.args.dim // self.args.n_heads, self.args.max_seq_len * 2, device=self.args.device)
def forward(self, tokens: torch.Tensor, start_pos: int):
batch_size, seq_len = tokens.shape
assert seq_len == 1, "Only one token at a time can be processed"
h = self.tok_embeddings(tokens)
# Retrieve the pairs (m, theta) corresponding to the positions [start_pos, start_pos + seq_len]
freqs_complex = self.freqs_complex[start_pos:start_pos + seq_len]
# Consecutively apply all the encoder layers
for layer in self.layers:
h = layer(h, start_pos, freqs_complex)
h = self.norm(h)
output = self.output(h).float()
return output