This blog summarizes the implementation of attention for encoder and decoder in transformer model.
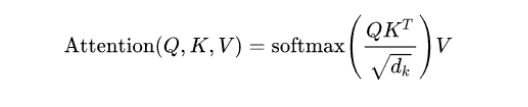
Pytorch Implementation
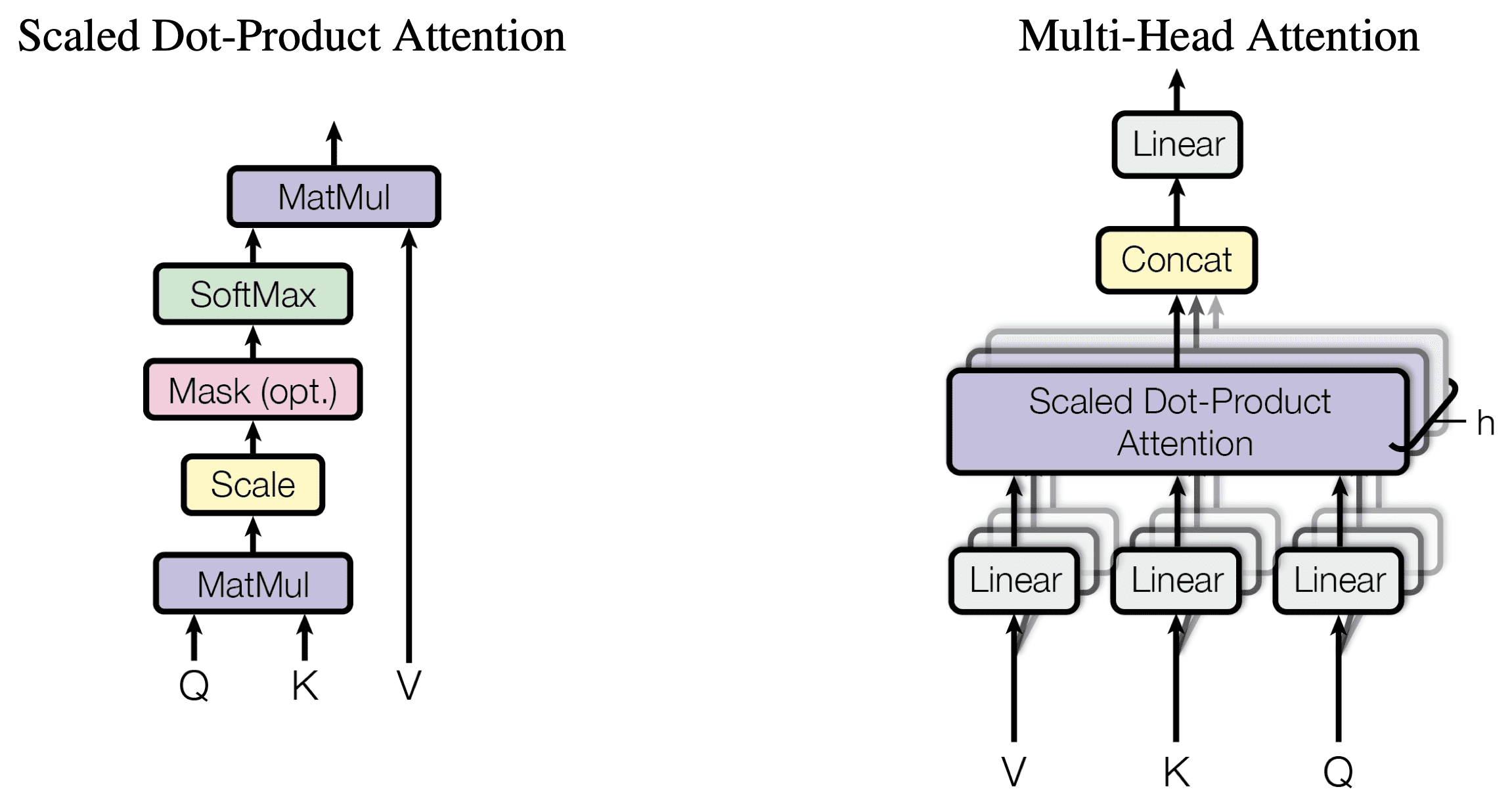
- Attention in transformer encoder (multi-head self attention)
Note: the reason why we need divided $\sqrt{d}$ during attention scores calculation:
1 |
|
- Attention in transformer decoder (mask multi-head self attention)
1 |
|
NumPy implementation
Attention in transformer encoder (multi-head self attention)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import numpy as np
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + b
def attention(q, k, v): # [n_q, d_k], [n_k, d_k], [n_k, d_v], [n_q, n_k] -> [n_q, d_v]
return softmax(q @ k.T / np.sqrt(q.shape[-1])) @ v
def mha(x, c_attn, c_proj, n_head): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projection
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
# split into heads
qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), qkv)) # [3, n_seq, n_embd] -> [3, n_head, n_seq, n_embd/n_head]
out_heads = [attention(q, k, v) for q, k, v in zip(*qkv_heads)] # [3, n_head, n_seq, n_embd/n_head] -> [n_head, n_seq, n_embd/n_head]
# merge heads
x = np.hstack(out_heads) # [n_head, n_seq, n_embd/n_head] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] -> [n_seq, n_embd]
return xAttention in transformer decoder (mask multi-head self attention)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import numpy as np
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + b
def attention(q, k, v, mask): # [n_q, d_k], [n_k, d_k], [n_k, d_v], [n_q, n_k] -> [n_q, d_v]
return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v
def mha(x, c_attn, c_proj, n_head): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projection
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
# split into heads
qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), qkv)) # [3, n_seq, n_embd] -> [3, n_head, n_seq, n_embd/n_head]
# causal mask to hide future inputs from being attended to
causal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype)) * -1e10 # [n_seq, n_seq]
# perform attention over each head
out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)] # [3, n_head, n_seq, n_embd/n_head] -> [n_head, n_seq, n_embd/n_head]
# merge heads
x = np.hstack(out_heads) # [n_head, n_seq, n_embd/n_head] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] -> [n_seq, n_embd]
return x
References:
- https://jaykmody.com/blog/gpt-from-scratch
- http://nlp.seas.harvard.edu/annotated-transformer/
- https://nlp.seas.harvard.edu/annotated-transformer/#encoder-and-decoder-stacks
- https://github.com/karpathy/nanoGPT
- https://github.com/jaymody/picoGPT
- https://github.com/Morizeyao/GPT2-Chinese
- https://github.com/ichbinhandsome/picoBERT
- https://github.com/ichbinhandsome/minGPT
- https://d2l.ai/chapter_attention-mechanisms-and-transformers/index.html
- https://github.com/zxuu/Self-Attention/tree/main
- https://github.com/ichbinhandsome/pytorch-transformer/tree/main
- https://zh.d2l.ai/chapter_attention-mechanisms/self-attention-and-positional-encoding.html