work harder, study better, do faster, become stronger
0%
MoE (Mix-of-Expert) Model
Posted onEdited onViews:
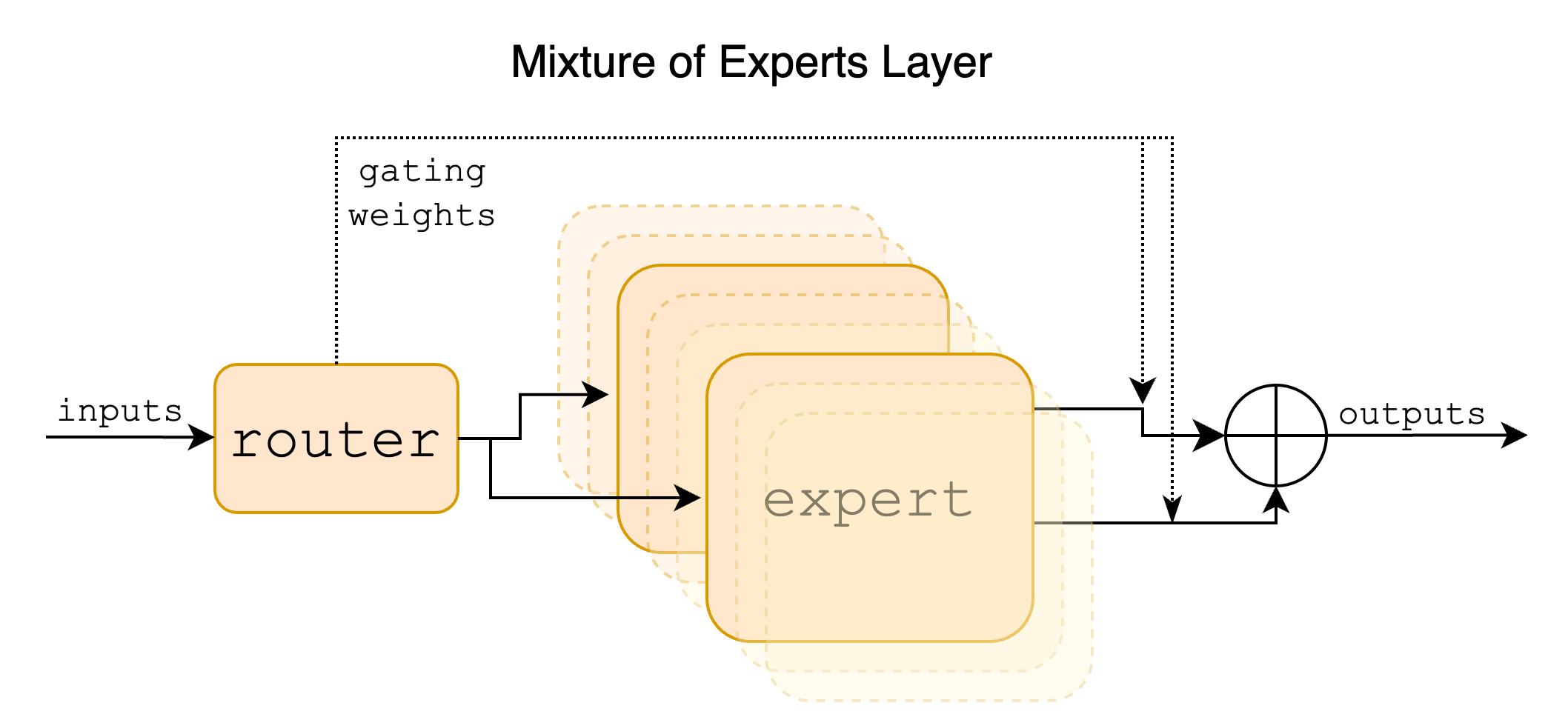
This image shows the basic structure of MoE. (source)
Recently Mixtral 8x7B MoE model dominate the open source models, as it shows on-par/better performance compared to open sources LLMs with more parameters. The MoE models have following features:
Achieve the same quality as its dense models and much faster during pretraining
Have faster inference compared to a model with the same number of parameters
Require high VRAM as all experts are loaded in memory
What exactly is a MoE? In the context of transformer models, a MoE consists of two main elements:
Sparse MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts”, where each expert is a neural network
A gate network or router, that determines which tokens are sent to which “expert”
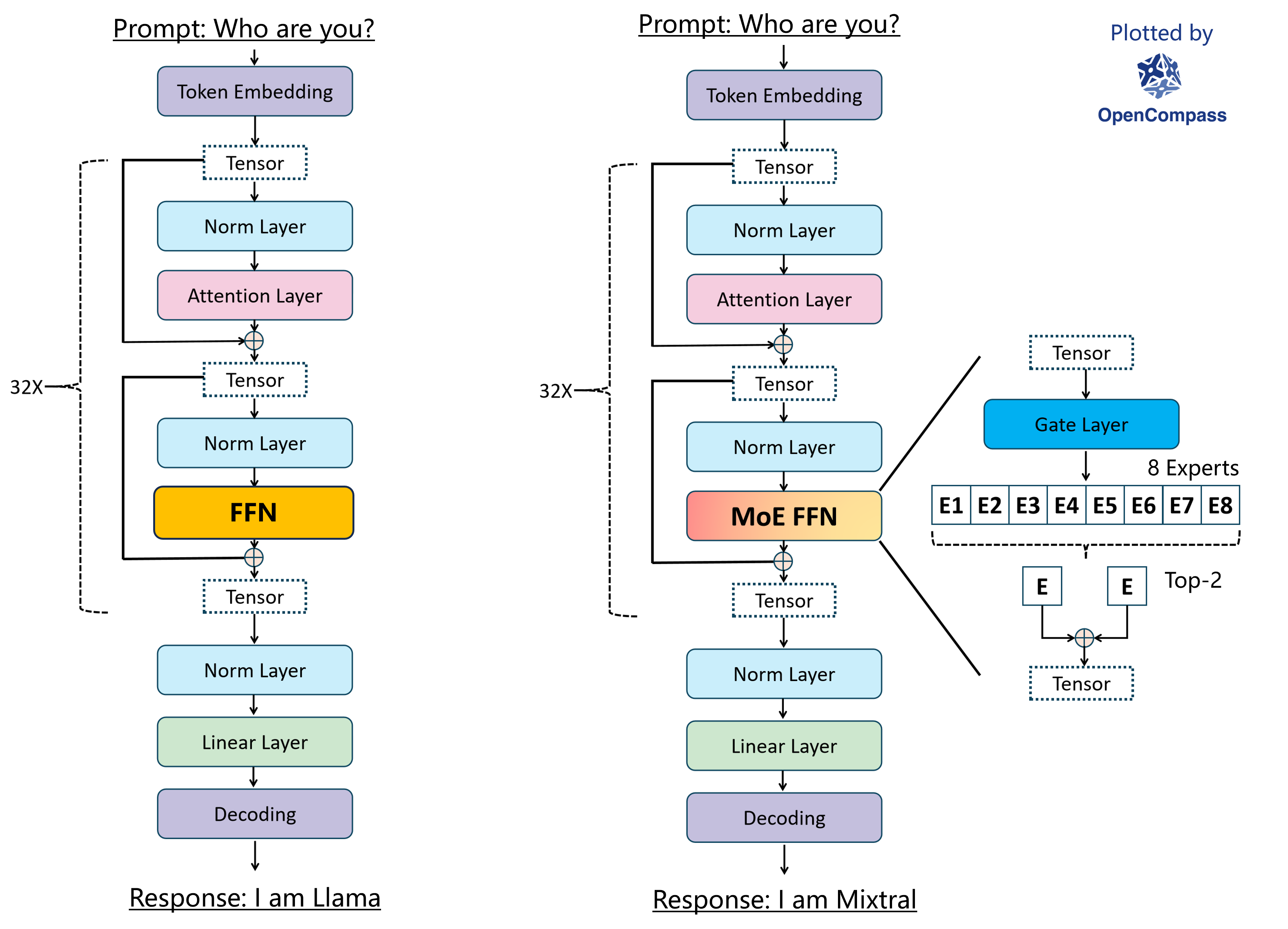
In Mixtral 8x7B MoE every FFN layer of the transformer model is replaced by an MoE layer, which is composed of a gate network and 8 experts. The gate network is a learned gating network decides which experts to send a part of the input. During training and inference, only 2 experts will be selected per token by the learned gating network.