During current advancement of LLM, many different attention methods beyond Multi-Head Attention (MQA) from original Transformer model have been proposed, such as Multi-Query Attention (MQA) from Falcon, Grouped-Query Attention (GQA) from Llama and Sliding-Window Attention (SWA) from Mistral. Both MQA and GQA aim to save GPU memory (i.e. reduce the size of Key & Value projection matrices during attention) and speed up attention calculation (i.e. reduce size of KV cache so that read data faster and support for large batch size) without too much model performance degradation. Sliding-Window attention (SWA) is a technique used in transformer models to limit the attention span of each token to a fixed size window around it, which reduces the computational complexity and makes the model more efficient.
This blog will implement all these different attention mechanisms from scratch using PyTorch.
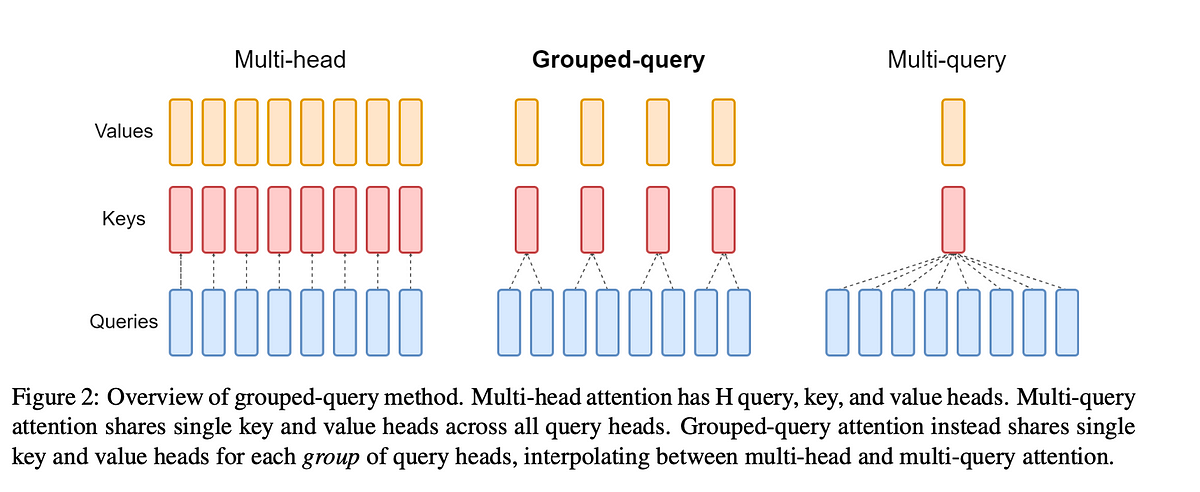
Multi-Head Attention
In Multi-Head Attention, each attention head computes its own unique set of query, key, and value vectors.
1 | class MultiHeadAttentionScores(nn.Module): |
Multi-Query Attention
The approach of MQA is to keep the original number of heads for Q, but have only one head for K and V. This means that all the Q heads share the same set of K and V heads, hence the name Multi-Query.
In general, MQA achieves inference acceleration through the following methods:
- The KV cache size is reduced by a factor of h(number of heads), which means that the tensors that need to be stored in the GPU memory are also reduced. The space saved can be used to increase the batch size, thereby improving efficiency.
- The amount of data read from memory is reduced, which reduces the waiting time for computational units and improves computational utilization.
- MQA has a relatively small KV cache that can fit into the cache (SRAM). MHA, on the other hand, has a larger KV cache that cannot be entirely stored in the cache and needs to be read from the GPU memory (DRAM), which is time-consuming.
1 | class MultiQueryAttention(nn.Module): |
Grouped-Query Attention
In Grouped-Query Attention, the number of unique Key and Value vectors is equal to a hyperparameter G, the number of Groups. For example, if the number of attention heads is 8 and G = 2, then there will be two unique sets of Key and Value vectors, each of which will be used by four attention heads.
GQA strikes a balance between the speed of MQA and the quality of MHA, providing a favorable trade-off.
GQA offers more efficient model parallelism across different GPUs, i.e. when operating in a multi-GPU environment with tensor parallelism, we can essentially get these performance gains for free by setting G equal to the number of GPUs.
llama2 original implementation: code In their implementation, we can see the project matrix W_k and W_v have smaller size num_kv_heads * head_dim (num_kv_heads is G) than W_q num_attention_heads * head_dim. During calculation, the code expands the Key and Value with repeat_kv(x: torch.Tensor, n_rep: int) so that Key And Value have same shape of Query: x[:, :, :, None, :].expand(bs, seq_len, n_kv_heads, n_rep, head_dim).reshape(bs, seq_len, n_kv_heads * n_rep, head_dim). Therefore, GQA doesn’t reduce the computation complexity of attention mechanism compared to MHA (Similar to MQA), it reduces the GPU memory cost of attention (i.e. Key, Value project matrices).
1 | class MultiHeadAttentionScores(nn.Module): |
Sliding-Window Attention
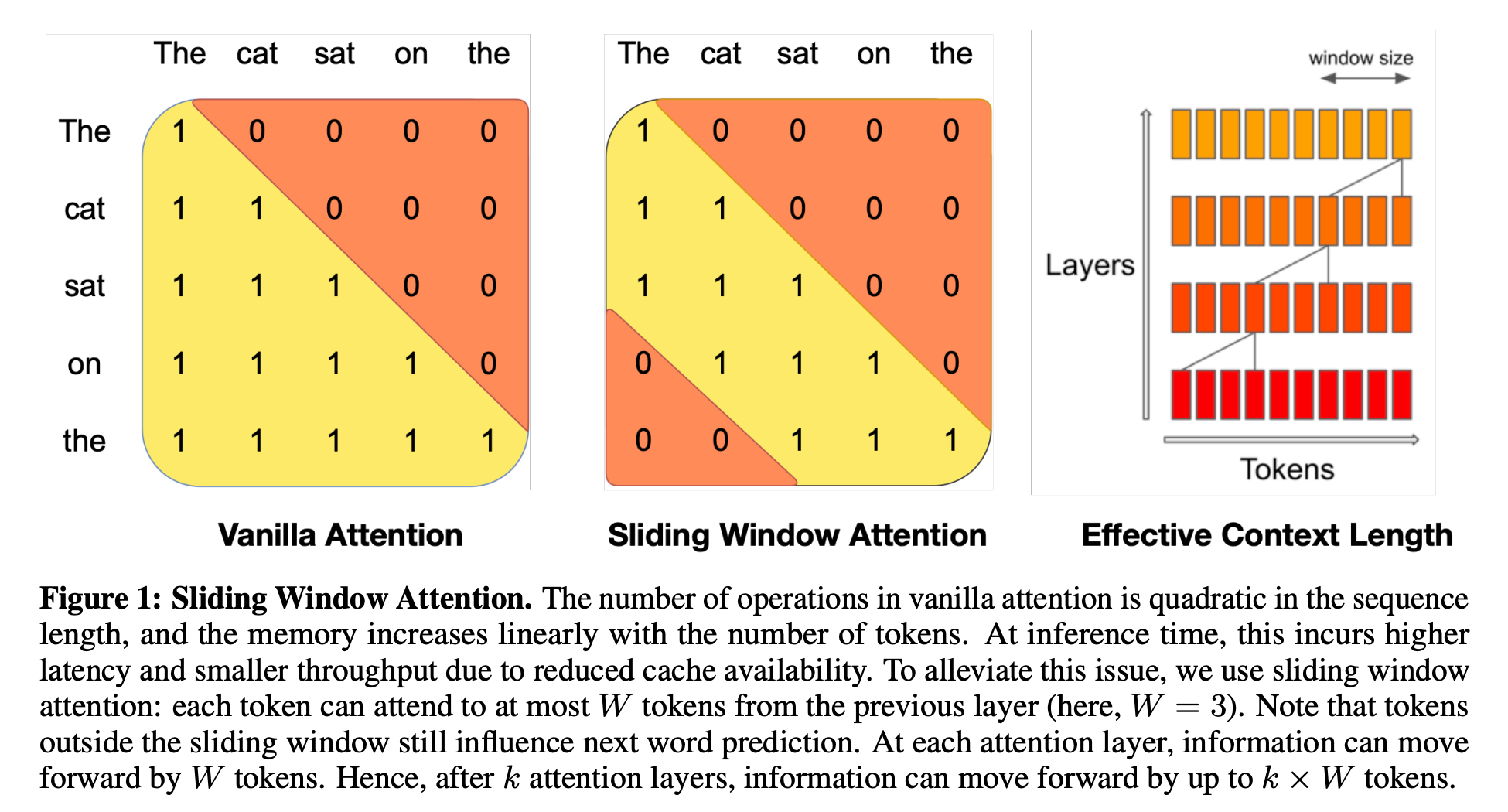
Given the importance of local context, the sliding window attention pattern employs a fixed-size window attention surrounding each token. Using multiple stacked layers of such windowed attention results in a large receptive field, where top layers have access to all input locations and have the capacity to build representations that incorporate information across the entire input. To make this attention pattern efficient, window size w should be small compared with sequence length n. But a model with typical multiple stacked transformers will have a large receptive field. This is analogous to CNNs where stacking layers of small kernels leads to high level features that are built from a large portion of the input (receptive field). In this case, with a transformer of l layers, the receptive field size is l x w (assuming w is fixed for all layers).
Here is how Mistral implement SWA in KV cache: code
A naive PyTorch implementation of SWA:
1 | class SlidingWindowMultiheadAttention(nn.Module): |
References
- https://pub.towardsai.net/multi-query-attention-explained-844dfc4935bf
- https://tinkerd.net/blog/machine-learning/multi-query-attention/
- https://blog.nghuyong.top/2023/09/10/NLP/llm-attention/
- https://github.com/facebookresearch/llama/tree/main
- https://medium.com/@manojkumal/sliding-window-attention-565f963a1ffd
- Mistral paper: https://arxiv.org/pdf/2310.06825.pdf
- https://www.ainavpro.com/3938.html
- https://github.com/mistralai/mistral-src/tree/main