主要流程
Query ==> Knowledge Base (Q-A Pair) ==> Answer
原则:猜你所想,答你所问
相关领域:搜索+自然语言处理+推荐
相关概念
Query
通常是指用户输入的查询语句,我们需要通过这个查询语句来定位其在知识库中所对应最可能答案
对一个用户Query进行语言理解的输出就是三个部分,分别是Domain,即这个Query是哪个领域的,Intent,即这个Query在表达什么意图;Slot,即这个Query里包含了那些重要的信息,可以作为后续任务触发的参数
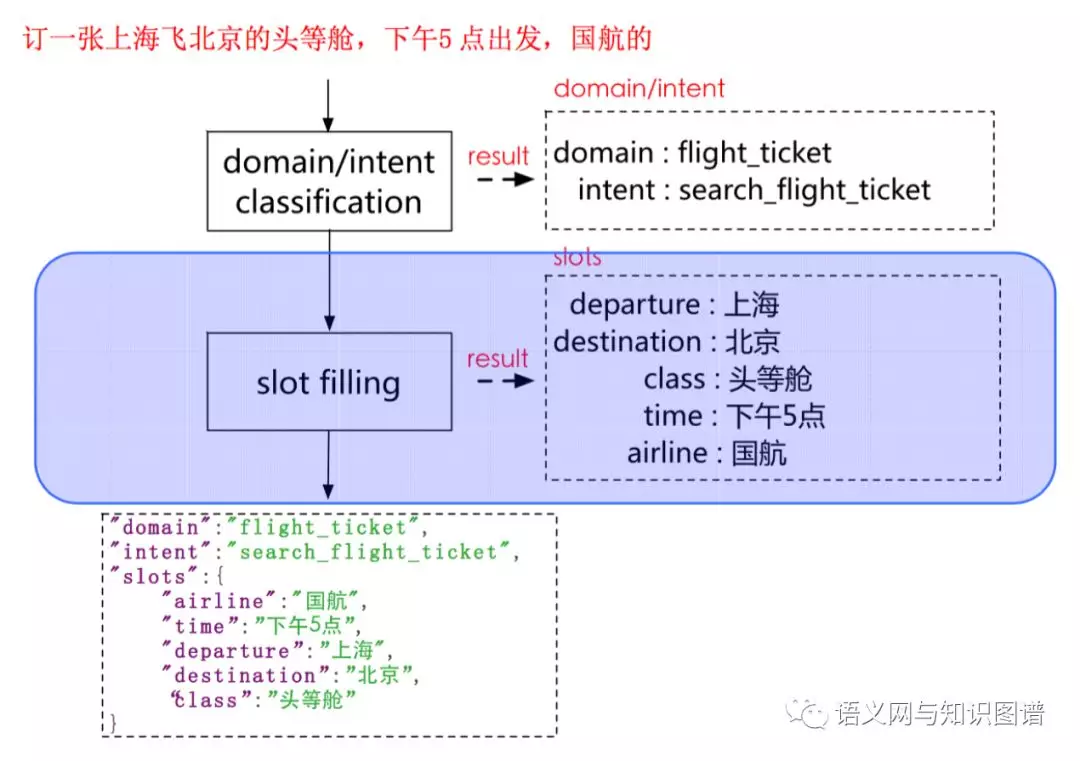
难点:query的表示方法,对用户query的语义理解,当query 信息不足时展开多轮对话,在知识库中对query的答案定位,用户的表达方式灵活多样,即同一个语义有多种表达方式
Knowledge Base
- 知识库一般是存储问题以及相应答案的数据库,里面的一个元素通常是二元组 <Question, Answer>
- 可以按照问题的种类以及业务相关知识先将 <Question, Answer> 分成几大类
- 知识库的构建往往是非常关键的,而且需要大量人力的投入
- 问答对也可以再进行扩充和优化,因为不同的人可能会有不同问问题的方式,可以将问答对扩展为多对一关系,比如多个相似问题对应着一个答案
- 进阶难点:将传统知识库转换成知识图谱,因果推理,关系抽取,实体抽取
对话系统
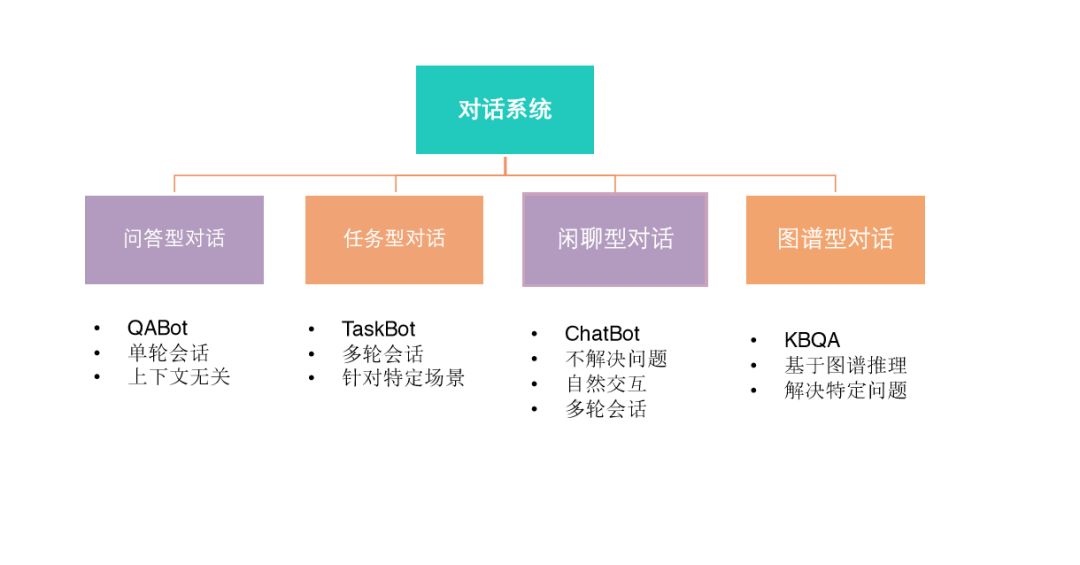
实现方案
1. 基于问题相似度的匹配(召回+排序)
用户的 query 本质上相当于一个问题,我们采用单论对话的方式,在知识库中快速找到和query相似的 TopK 个问答对,将其返回给客户(快速召回)
方法:比较query和知识库中的问题,找到最相似的TopK,再进行排序
a. 词语维度匹配:关键词匹配,编辑距离(字符级召回)
b. 文本向量维度匹配:Bag-Of-Words, TF-IDF, LSA (潜在语义分析),Doc2vec,主题模型(向量级召回)
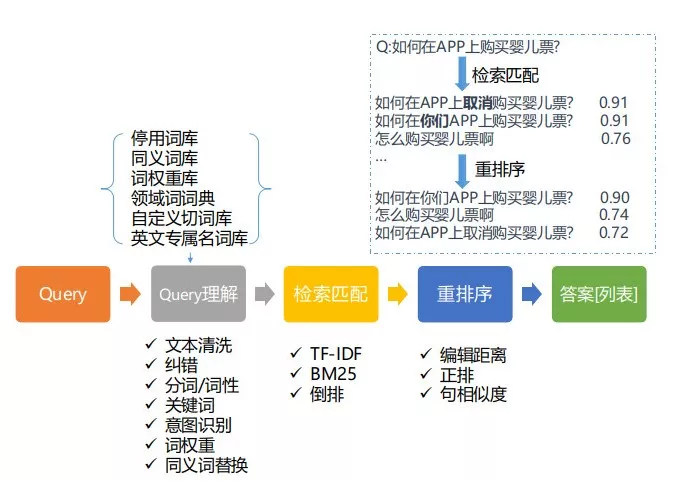
去哪儿基本问答流程 缺陷:用户输入的问题往往不够精确,如果不进行处理就进行匹配的话可能会产生错误的答案;需要维护大量的同义词典库和匹配规则;召回需要耗费大量的时间
进阶:微软的DSSM模型(句子级别上的神经网络语言模型)在解决短文本语义匹配上有很好的效果
2. 问题分类
意图识别:可以先将知识库分为三个维度:”是什么“, ”为什么“, ”怎么做“。然后对用户的query做一个简单的文本分类(意图识别),对于这三个不同类别的意图采取不同的匹配策略,如:”是什么“往往是对专有名词术语解释,只需要做简单的文本匹配。”为什么“和”怎么做“ 可能就需要更为复杂的实现方法
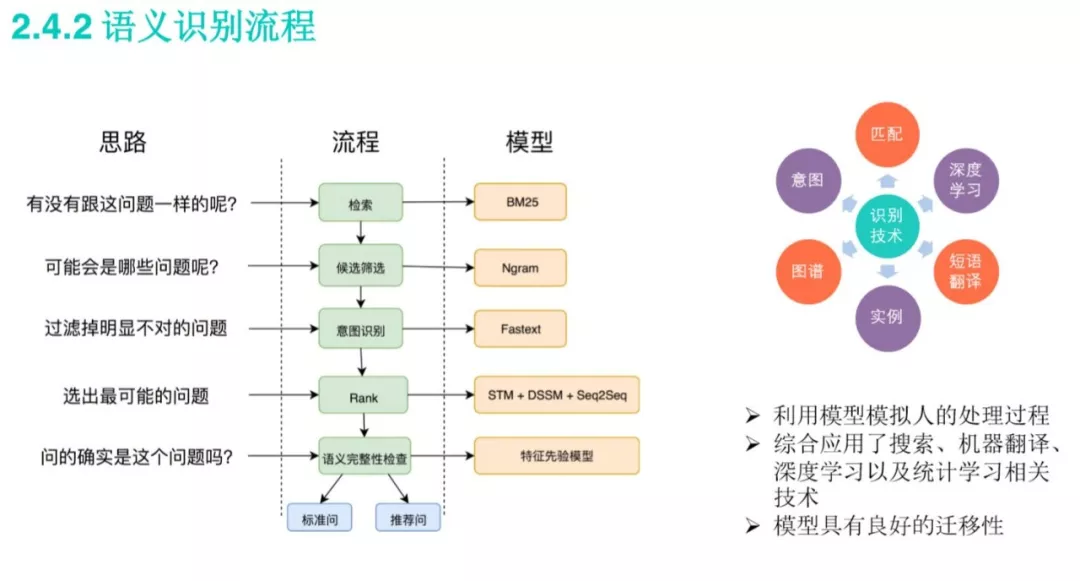
美团语义识别流程 问题分类:将知识库中不同意图下的问答对再根据业务场景进行划分,比如”saas相关“或者”paas相关“,也可以分割为更为精细的维度。当已经识别出用户的意图时,对query再次进行文本分类(使用BERT,FastText、TextCNN和Bi-LSTM),得到对应问题的子类,然后再进行语义匹配
主要思想:召回+粗排+精排
相关的语义匹配任务可以参考百度的 AnyQ Framework
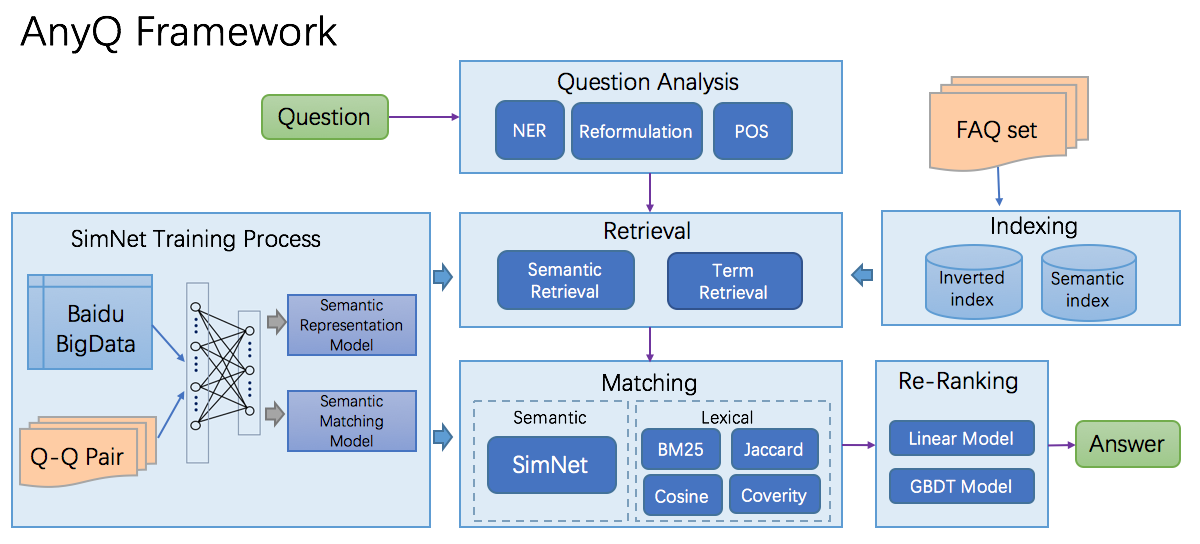
缺陷:需要大量的知识库问题对来训练模型,用户的问题可能涉及到了多个领域,单个query可能无法获取准确有效的信息
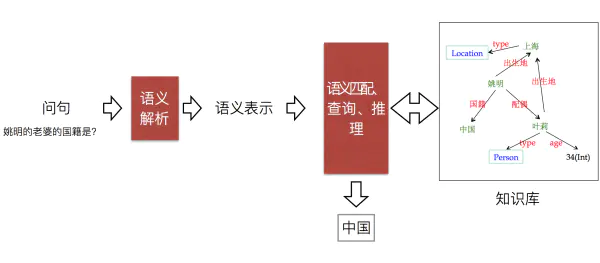
3. 知识图谱+NER+信息检索
主要流程:知识图谱构建与存储、语义解析、查询语句执行、答案与回复生成
通过对传统的的知识库中的元素进行实体抽取,关系抽取,事件抽取来构建知识图谱
先对用户的query进行意图识别
再对query进行实体抽取和关系抽取(NER)
再知识图谱中进行因果推理和信息检索
4. 多轮对话
意图分析+场景识别+槽位填充
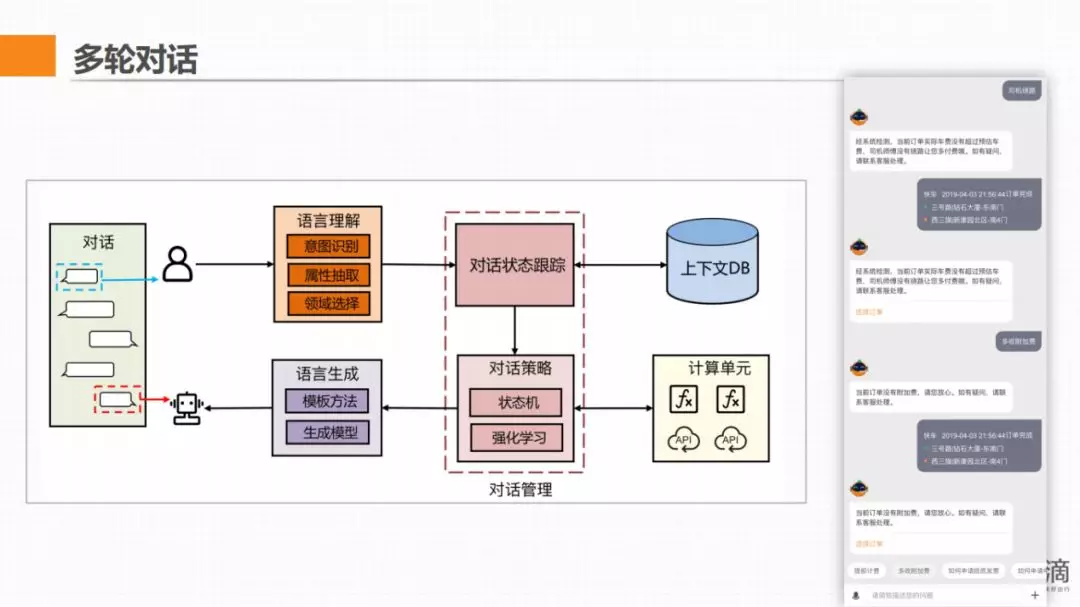
滴滴客服中多轮对话模型 多轮是一个更偏工程的过程。里面更多的算法是在做槽位解析,需要做好三件事,第一个就是填槽,如果对话过程中槽位未补全,在下轮对话过程中引导用户补全槽位信息。再者就是场景管理,需要维护海量用户的聊天信息。第三点就是可配置,多轮最后面都是一个业务问题,开发一个可配置的界面,让运营自行配置其需要的对话。多轮的逻辑是在知识库里配置的,DM是和业务无关的,只需要按配置的解析结果执行即可
找到所有信息后再在知识库中进行检索匹配
优化方案
input suggestion
- 根据用户输入问题来自动生成后续的话,一方面节省用户时间,另一方面能更为精确地描述和匹配用户问题
- 可以使用规则匹配使用字典树 Trie(需要维护大量规则),也可以语言模型预测
待续…